

As we dive into the evolving world of natural language processing (NLP), it’s impossible not to marvel at the capabilities of large language models (LLMs). In our Chief Data Scientist, Jon Krohn’s, recent SuperDataScience podcast episodes, he has been exploring the potential of open-source LLMs like Vicuña, a tool that approaches the state-of-the-art capability of GPT-4 but with significantly fewer parameters. These models typically range from 1 billion to 13 billion parameters, making them smaller, faster, and more cost-effective for production use.
Our focus has been on how these powerful yet compact LLMs can be fine-tuned for a variety of natural language tasks using a single GPU. Particularly noteworthy is the parameter-efficient fine-tuning approach discussed in Episode #674, which further enhances the appeal of these models for real-world applications.
However, it’s essential to acknowledge the limitations of these open-source alternatives. One significant drawback is their smaller context windows compared to GPT-4. A context window, for those unfamiliar, refers to the number of tokens (think of them as pieces of words) that a model can consider at once. This is crucial for understanding and generating language based on the given context. While a special version of GPT-4 boasts a context window of 32,000 tokens (approximately 50 pages of text), open-source models like Vicuña might be restricted to 500-1000 tokens due to computational constraints. This limitation can be significant for tasks requiring a broad understanding of context or lengthy document processing.
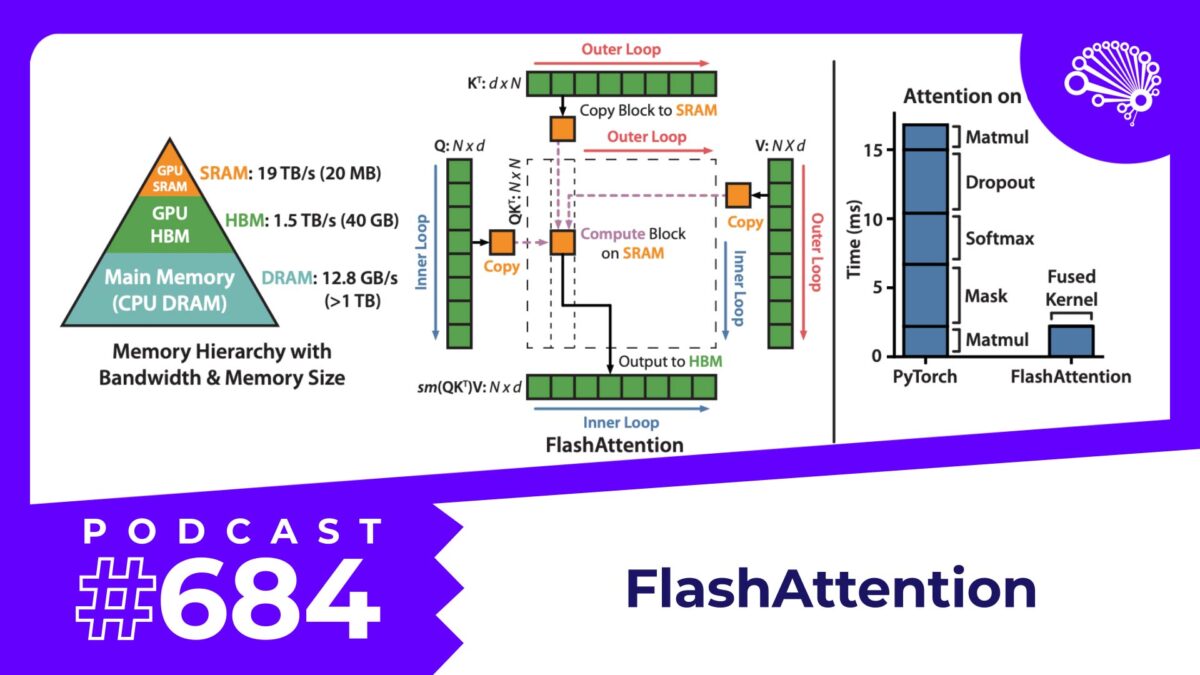
To address this challenge, researchers have developed innovative solutions like FlashAttention. This method, pioneered by a team at Stanford University, has shown impressive results, speeding up model training by 3 times and attention at inference time by 7 times when using GPT-2 as a benchmark. The larger the sequence your LLM needs to process, the more you stand to benefit from FlashAttention.
In conclusion, while open-source LLMs like Vicuña offer a more accessible entry point to powerful language processing capabilities, it’s important to consider the trade-offs in context size and processing speed. With ongoing research and development, tools like FlashAttention are continuously improving the efficiency and performance of these models, promising an exciting future for the field of NLP.
The SuperDataScience podcast is available on all major podcasting platforms, YouTube, and at SuperDataScience.com.


